






2018年6月19日~2018年7月9日にかけて、ファーストサーバー会社のレンタルサーバーZenlogicで起きた大規模障害事件について、こんな疑問はありませんか?
障害事件についての疑問
- そもそも、ファーストサーバー会社って一体どんな会社なの?
- 今回の障害事件でyahooはどう関係しているの?
- Zenlogicサービスを利用していたユーザーは一体どんな被害を受けたの?
- 被害を受けたユーザーへの返金保証ってあるの?
- なにが原因でこんな障害事件が起きたの?
 クロネコくん
クロネコくんたしかに障害の原因を簡単に教えて欲しいし、返金保証があるのか気になるし、yahooがどう関係しているのかも知りたいな。
そこで、この記事では以下のことについてまとめてみました。
この記事で紹介することについて
- ファーストサーバー会社の簡単な紹介
- Zenlogicサービスにおけるyahooの役割について
- 今回の障害でユーザーが受けた被害について
- 障害に対するユーザーへの返金について
- 障害発生~完全復旧までの時系列を解説
- 障害事件の原因を図解つき簡単解説
- 今回の障害事件から我々ユーザーが学ぶべきこと
ざっくりとした解説ではありますが、これさえ読めば今回のファーストサーバー障害事件の全貌がより分かるかと思います。
ファーストサーバー障害事件について詳しく知りたい人や、レンタルサーバーを利用する上で障害に対してどう備えておくべきかを知りたい人は読んでみてください。
ファーストサーバーとは?
クロネコくんまず始めに、今回の障害事件を起こした「ファーストサーバー」社って、どんな会社なのかを間単に紹介するよ。
ファーストサーバーとは「Zenlogic」という、中小企業向けのレンタルサーバー・ドメイン・SSLサービスを行っている会社です。
 サバくん
サバくんターゲットは中小企業だけど、個人でも契約して利用可能だよ。
これまで累計72000企業以上で利用(契約)があり、さらには官公庁(国や地方公共団体の役所)でも利用(契約)されています。
また、2004年~2018年2月まではyahoo(ヤフー)が親会社、2018年3月からはyahooに代わってソフトバンクが親会社となっています。
yahoo → ソフトバングが親会社という圧倒的ブランド力と72000社以上の利用実績を背景に躍進を続ける大手レンタルサーバー会社です。
Zenlogicサービスにおけるyahooの役割
ファーストサーバーでは2015年1月までは、サービスの契約~レンタルサーバーの管理までの全てを自社のみで行っていました。
しかし、2015年2月からサービス業1本に集中するため、レンタルサーバーの管理はyahooが行うようになりました。
また、それに合わせて今のサービス名であるZenlogicと名乗るようになりました。
サバくんZenlogicにおける、ファーストサーバー・yahoo・ユーザーの関係は以下のとおりだよ。
■Zenlogicの概要
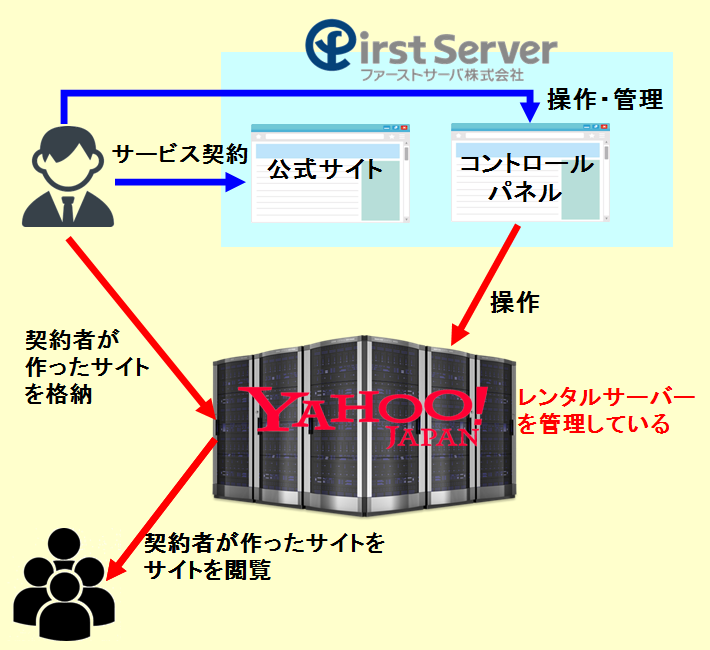
クロネコくんなるほど。肝となるレンタルサーバーの管理だけはyahooがしているってことか。
サバくんそういうことだね。
サバくんそして、yahooは今回の障害事件を起こしたそもそもの原因主でもあるよ。
障害による影響範囲

Zenlogicには2つのサービスがあります。
Zenlogic2つのサービス
- 利用料金が安く(月額890円~)スタンダードな性能で、yahooがサーバー管理をしている「Zenlogicホスティング」
- 利用料金が高い(月額9810円~)代わりに高性能で、AWS(Amazon)がサーバーを管理している「Zenlogicホスティング Powered by AWS」
今回障害が起こったのはyahooがサーバー管理をしている「Zenlogicホスティング」であり、「Zenlogicホスティング Powered by AWS」には障害が発生していません。
クロネコくんなるほど。Aws(Amazon)がサーバー管理している方は、何もなかったってことか。
サバくんその通りだよ。さすがは天下のAmazonってところだね。
また、「Zenlogicホスティング」のほうが利用者が多いため、より多くのユーザーが障害による被害を受けることになりました。
障害事件でユーザーはどんな被害を受けたの
今回の障害事件によって「Zenlogicホスティング」を利用していたユーザーは以下の被害を受けることになりました。
■2018/6/19(火) ~ 2018/7/5(木)まで。
障害事件によってユーザーが受けた被害
- Zenlogicのメールサービスによるメール送信や受信が通常より遅くなった
- 作ったサイトやブログへのアクセスが遅くなったり、アクセス自体が失敗することがあった
- 契約したZenlogicサーバーへのファイル転送が遅くなったり、ファイル転送自体が失敗することがあった
- Zenlogicコントロールパネルの動作が遅くなった
■2018/7/6(金)~ 2018/7/9(月)まで。
障害を復旧するためにファーストサーバー社がZenlogicにおける全サービスを停止してのメンテナンスを実施したことにより、ユーザーは以下4つの被害を受けた。
全サービス停止によりユーザーが受けた被害
- Zenlogicのメールサービスによるメール送受信が一切できなくなった
- 作ったサイトやブログへのアクセスが一切できなくなった
- 契約したZenlogicサーバーへのファイル転送が一切できなくなった
- Zenlogicコントロールパネルへアクセスと操作が一切できなくなった
サバくん全サービスが停止したことにより、ユーザーはサイト・ブログを他サーバーへの引越しもできず、文字通り「指を加えて様子を見ていることしかできない」最悪の事態となったよ。
Zenlogic利用ユーザーによるツイート(Twitter)まとめ
クロネコくん今回の障害事件でZenlogicを利用していたユーザーの反応はどんな感じだったんだ?
サバくん当然ファーストサーバー社とサーバーを管理していたyahooに対する「怒り・不満・悲しみ」の反応ばかりだったよ。
■ユーザーによるツイート(Twitter)まとめ
https://t.co/s3ef0pOwGi
Zenlogic ここまで能力の無いクラウド業者も珍しいな。週間サーバートラブル。今日のメンテナンスも予定大幅遅れで、しかも完了未定ときたもんだ。勿論原因の説明は無し。これでもこの業者を選ぶ技術者がいたら、自殺願望があるとしか思えない— 藤原@かみら💨💸(・ω・´) (@Racer_Kamira) 2018年7月2日
急遽、サーバ会社を変更したけど、DNS変更できないって何なんだ!!!電話もつながらんし、メールフォームからメールしても自動応答だし。お願いだからせめてDNSだけでも変更させてくれ仕事にならん#zenlogic
— yucyunpa (@yuzu1113) 2018年7月4日
7/1 ログ出力が間違ってたぽい。修正したからOK
7/2 あ、ごめん直って無かった。助けて親会社Yahoo、つーかお前のせい。
7/3 徐々にいい感じ。5日の昼にはバッチリ
7/4 サーバーに負担がかかる時間帯はダメですが5日の昼にはバッチリ
7/5 あ、ごめんやっぱり6日でよろ~
7/6 今週中無理ぽ #zenlogic— バイバイアンフォロワー (@bbu_app) 2018年7月6日
おはようございます…目覚めが悪い朝でした。
サーバーが全停止しているので当たり前ですが受注件数ゼロです。
こんな事は前代未聞、これが後48時間も続くと思うと死にそうです。
どうか皆様、私が生きているうちに先に香典をください🥶#Zenlogic #ファーストサーバ pic.twitter.com/yBY3WmOzDq— 問屋@ショップ (@tonya_at_shop) 2018年7月6日
Zenlogicなんとか普及したっぽいが、はっきり言っていつまた同じようなことがおきるかわからない。なんせ6年前の大規模障害から何も学んでないんだから。アホは死んでも治らないね。
このまま使い続けるとこちらの信用が落ちるのでさっさと他社に移行します。さようなら。#zenlogic #ファーストサーバ— mashdogs (@mashdogs) 2018年7月11日
喜べない計測結果😰#Zenlogic #ファーストサーバ #Analytics pic.twitter.com/zyJIUQZWHD
— Amen0ma1 (@amen0ma1) 2018年7月18日
さらには著名者まで、この障害はさすがに「ひどい」とのツイートが
これはひどすぎ
ファーストサーバの「Zenlogic」全面停止3日間続く 再開は「未定」に (ITmedia NEWS) – https://t.co/6O3bQSe5xE— 堀江貴文(Takafumi Horie) (@takapon_jp) 2018年7月9日
クロネコくんうわ、当然のように怒りや失望の声ばっかりだな。
サバくんそうだね。でも、このユーザーの声こそが今回の障害事件の大きさを物語っているとも言えるよ。
障害を受けた人への返金や損害賠償はどうなるのか?
クロネコくんサイトが3日も止まるほどの被害なら、ユーザーからの返金要求も相当のものになるんじゃないのか?
サバくんそれがそうでもないんだよ。今回ファーストサーバーが障害において返金に応じるのは、サービスが停止した月の月額料金の一部だけになりそうだと言われているよ。
クロネコくんなんでだよ。おかしいだろ。
レンタルサーバー会社のサービス品質規約SLAとは
SLA(サービスレベルアグリーメント)を一言でいうと、レンタルサーバー会社とユーザーとの間で結ばれるサービスの品質規約です。
また、ユーザーがファーストサーバー社のZenlogicサービスに契約した時点でSLAにも同意したとみなされます。
そして、サービスの品質規約とは「レンタルサーバー会社とユーザーにおける正常なサービスの提供条件と条件を満たさなかった場合の返金について」の約束事になります。
■ZenlogicサービスのSLAについて
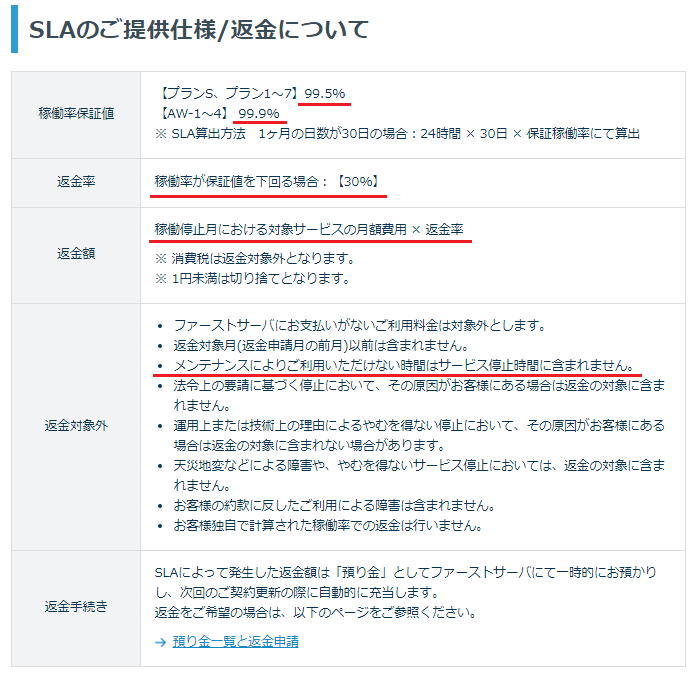
上記のZenlogicサービスのSLAを要約すると以下のようになります。
ZenlogicのSLA要約
- 下位プランなら月間稼働率99.5%、上位プランなら月間稼働率99.9%を下回ったら返金対象となる
- 稼働率はサーバー(サービス)が停止していたら下がっていく(異常でも動いていたらセーフ)
- 返金額はユーザーが契約しているプランの月額料金の30%となる
- そもそも今回の障害事件を解決するためのサービス停止はメンテナンスに当たるから、返金対象外の可能性もある
クロネコくんはあ、なんだよこのクソみたいな規約は?
クロネコくん月額料金の30%だけの返金で、しかも場合によっては返金対象外にもなるってどうみてもおかしいだろ。
サバくん残念ながらファーストサーバーだけじゃなく、どのレンタルサーバー会社のSLAも似たような規約になっているよ
原則としてレンタルサーバーを利用してのサイト運営で稼げたはずの金額をレンタルサーバ会社ーによる意図しないサーバー停止によって失っても、それがレンタルサーバー会社の故意または重過失が原因によるものだと認められない限り、SLAに記載されている金額しか返金されません。
サバくん酷な話ではあるけど、今回の障害事件は故意ではなく過失にあたり、その過失自体も重過失に相当するのかは非常に怪しいところだよ。
クロネコくんはあ、なんでサービスが3日も停止する障害が重過失にならないんだよ。
サバくんその気持ちは充分に分かるけど、そもそも重過失の基準ですごく厳しいんだよ。
重過失と重過失による返金額について
重過失とは
重大な過失、不注意ないし注意義務違反の程度がはなはだしいこと。
民法上は善良な管理者の注意義務を著しく欠くこと。
刑法上は通常人の払うべき注意義務を著しく欠くこと。
このように重過失は著しい不注意や会社で定められたマニュアル(規定)以外のことを一部社員が独断で行ったことが原因によって障害事件が発生した場合でないと、重過失の障害事件とはみなされません。
後述はしていますが、今回の障害では技術的に明らかな問題があったのは事実です。
しかし、経営者やエンジニアの著しい不注意や独断行動で発生した障害ではなく、ユーザーの資産となるサイトやデータも消失したわけありません。
ですので、2週間に及ぶサービスの影響と3日間のサービス完全停止のみで重過失になるかは怪しいというわけです。
クロネコくん重過失の基準って、こんなに厳しいんだな。
サバくん故意に等しい過失があったり、障害による明らかな資産消失が認められないと重過失にするのは厳しいよ。
サバくんそして、さらに悲しいことに重過失が認められたとしても、損害賠償は最大で12月分の利用料金額にしかならないよ。
クロネコくんもう、悲しすぎてなにも言えないぜ・・・
■Zenlogicホスティング利用契約約款より

上記のZenlogicホスティング利用契約の記載にあるとおり、重過失が認められても「過去12ヶ月分の利用料金額」しか損害賠償として請求できません。
サバくん利用料金額はZenlogicへの月額料金やオプション料金のことだよ。
結論としては、ファーストサーバー社が寛大で自分から今回の障害は重過失であったと認めない限り。
法人(企業)はともかく、個人契約での重過失による損害賠償の請求は厳しいのが現実です。
■参考サイト
ファーストサーバ社のレンタルサーバ「Zenlogic」で大規模障害。利用者は返金や損害賠償を請求できるのか – Stori法律事務所
障害発生~復旧までの時系列のまとめ
サバくんここでは、今回の障害の発生~完全復旧までを詳しく追っていこう。
今回の障害でファーストサーバーが初めにユーザーへアナウンスを出したのが「2018年6月19日09時15分」で、完全に復旧を宣言をしたのは「2018年7月17日の08時30分」となっています。
では、ユーザーへ初めにアナウンスを出してから完全に復旧するまで、なにがあったのか順番に見ていきましょう。
2018/6/19(火)09:00 ~ 2018/6/19(火)09:30
ストレージシステムの高負荷が原因でレンタルサーバー全体が不安定となり。
その結果、ユーザーが作ったサイトの表示が遅くなったり、Zenlogicのコントロールパネルや契約しているレンタルサーバーへのFTP接続などが繋がりにくくなる現象が発生することをユーザーへアナウンスした。
2018/6/20(水)11:00 ~ 2018/6/20(水)11:30
ストレージシステムの高負荷が原因でのサーバーが不安定になる現象が自然解消したことをユーザーへアナウンス。
2018/6/21(水)12:30 ~ 2018/6/21(水)18:30
再びストレージシステムの高負荷が原因でレンタルサーバー全体が不安定となる現象が発生。
18:30頃に自然解消したことをユーザーへアナウンス。
2018/6/22(金)09:00 ~ 2018/6/22(金)14:00頃
ストレージシステムの高負荷が原因でのサーバーが不安定になる現象を根本的に解決するため、障害の兆候が見られたレンタルサーバーの入れ替えを行ったことをユーザーへアナウンス。
2018/6/23(土)02:00 ~ 2018/6/23(土)06/24(日)23:59
ストレージシステムの高負荷が原因でのサーバーが不安定になる現象の根本的な解決のために動き出す。
障害の原因となっているストレージシステムのキャパシティ(容量)不足を解消するため、ストレージシステムへサーバーの増強を行う。
クロネコくん障害解消に向けて働いてくれたエンジニアの人はご苦労様だぜ。
2018/6/25(月)16:30 ~ 2018/6/28(木)15:40
しかし、またストレージシステムの高負荷が原因でレンタルサーバー全体が不安定となる現象が発生。
この期間中で少し時間をおいて現象が自然解決される現象は合計3回も繰り返された。
クロネコくんうん、ここまできたら分かるぜ。障害は解決してなかったってことだな。
サバくん残念ながら、その通りだったよ。
2018/6/27(水)13:35~2018/7/3(火)15:30
毎日、ストレージシステムの高負荷が原因でのサーバーが不安定になる現象が発生 → ストレージシステムの増強作業 → 「原因は解消」のやり取りが繰り返される。
2018/7/4(水)8:40~ 2018/7/6(金) 15:45
これまで行ったきたストレージシステムの増強作業だけでは障害を解消できなかったので、さらなる原因調査及び解消作業に乗り出す。
ちなみに、この日から障害はさらに悪化して明らかにサイトの表示が遅くなったり、Zenlogicのコントロールパネルや契約しているレンタルサーバーへのFTP接続などが繋がりにくくなる現象が多発するようになった。
サバくんこの時点でもかなりの異常事態だけど、ここまではさらなる異常事態へのプロローグでしかなかったんだ。
サバくんなんだよ、これよりひどい事が起きるのかよ。
2018/7/6(金)20:00 ~ 2018/7/9(金)23:00
完全な復旧にはサービス全体の停止が必要と判断されて、「2018/7/9(金)23:00」までサービス全体が停止しての超大規模メンテナンスが実施される。
そのあいだ、サイトの閲覧・コントロールパネルの操作・FTP接続などは一切できない状態となり、「Zenlogic」利用ユーザーは阿鼻叫喚状態となる。
ちなみに、サービス全体の停止がユーザーへアナウンスされたのはサービス停止の1時間前の「2018/7/6(金)19:00」だった。
サバくん始めは1日だけのサービス停止予定だったんだ。しかし障害は解消せずに連日メンテナンスが延長された結果、3日間のサービス停止という超異常事態にまでなったよ。
クロネコくん3日間もレンタルサーバーのサービスが停止するなんて聞いたことがないぜ。新作リリースされたガチャゲーの緊急メンテかよ。
2018/7/9(金)23:00 ~ 2018/7/17(火)08:30
「2018/7/9(金)23:00」にようやくメンテナンスが完了してサービスがようやく再開となる。
以後「2018/7/16(月)」まで経過観察とyahooによる障害報告のまとめが行われる。
「2018/7/17(火)08:30」に完全に復旧したことがユーザーへアナウンスされた。
また、yahooによる障害の原因と対応の報告書がZenlogicのホームページを通じてユーザーが閲覧できるようになる。
サバくん3日に渡る全サービスの停止。合計70回に及ぶユーザーへのアナウンスが行われた、レンタルサーバー業界において前代未聞の大規模障害事件はこれで一応の終息となったよ。
クロネコくんなんかもう、ゴジラが暴れ回った後の町に戻る気分だぜ。
障害の原因と不味すぎた対応
今回の障害原因をまとめると以下のようになります。
※この記事で記載している障害の原因はファーストサーバーが出した自己報告書から推測結果ですので、100%正しい答えではないことをご了承ください。
また、以下で使っている画像は概要をイメージしたものですので、データ量などは実数値ではありません。
1.「Zenlogicホスティング」でサーバーを管理しているyahooではデータを複数のサーバーに格納していた。
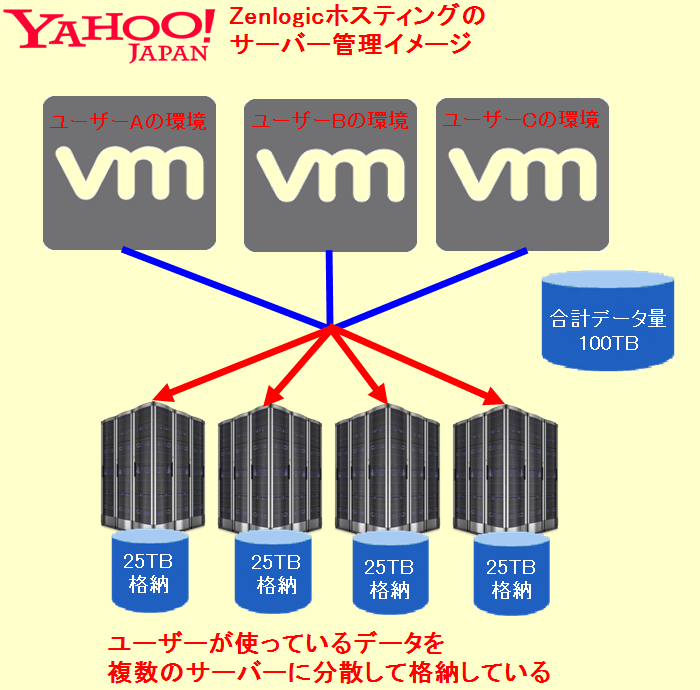
クロネコくんなんで、わざわざデータを分けて格納するなんて面倒くさいことしてるんだ?
データを複数サーバー(ストレージ)に分けて格納しておくことで、1つのサーバー(ストレージ)が障害でつぶれても素早く復旧することが出来るので障害に強くなるメリットがあります。
サバくんちなみに、この技術は「分散ストレージ」っていうんだ。
クロネコくんでも、障害に強くなるとかいって、ここまでの大規模障害になってるのはどういうことなんだ?
ただし、分散ストレージは正しく運用できないと今回のような大規模障害を起こしてしまうデメリットがあり、今回の障害はそのデメリットに該当する結果となりました。
2.ファーストサーバーやyahooが当初想定していたよりも多くのデータ量となり、用意していたサーバー(ストレージ)だけでは格納しきれなくなった。
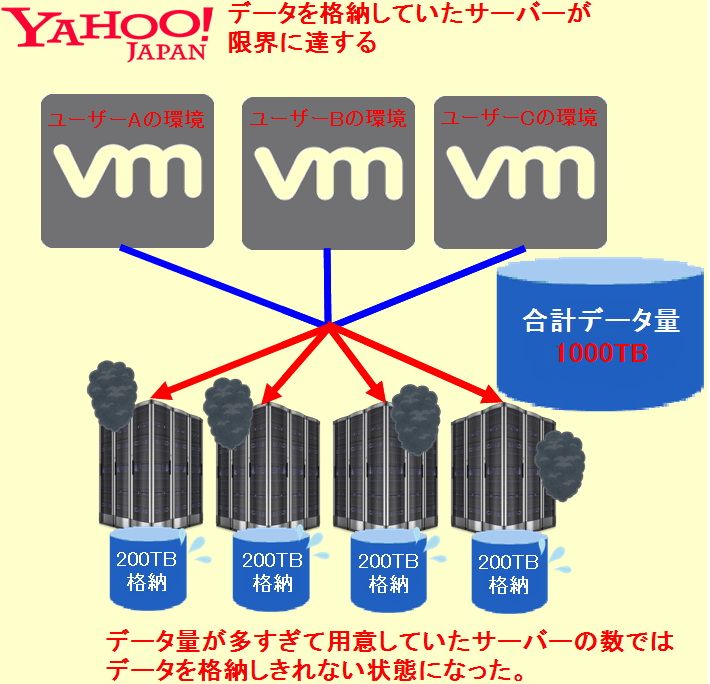
サバくんようするに当初用意していたサーバー(ストレージ)だけではデータを格納しきれなかったんだ。
クロネコくんなるほど、見積もりが甘かったってことだな。
サバくんそういうことだね。コストを抑えようと投入するサーバーをギリギリにしようとしたのが失敗だったと思うよ。
また、この時点(2018年6月19日)でサイトやメールの送受信などが遅くなるような障害が発生しており、ユーザーへも障害としてのアナウンスが始まりました。
4.全てのデータを格納して障害を解決するためにサーバー(ストレージ)を増やした。
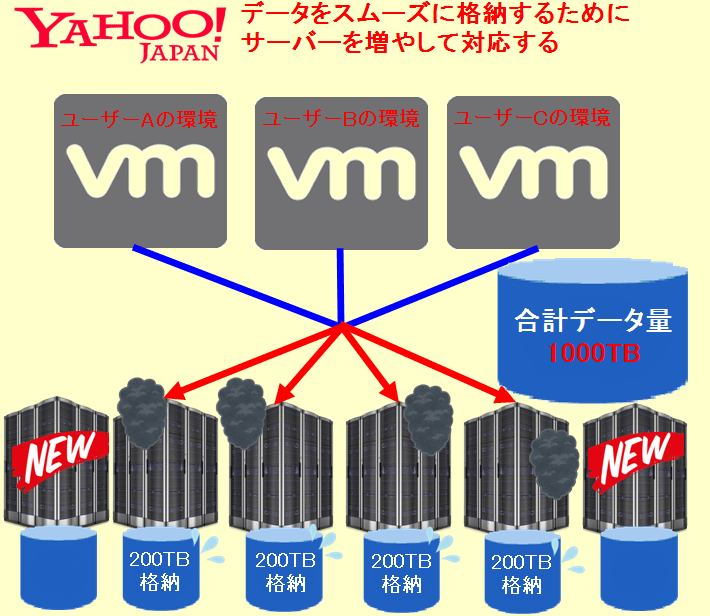
クロネコくんこれが何度もアナウンスされていた「ストレージシステム」の増強作業ってことか?
サバくんその通りだよ。でも、サーバーを増やしてある作業をしないと分散ストレージは機能を発揮できないんだ。
5.用意されたサーバー(ストレージ)へデータの再配置処理を行った。
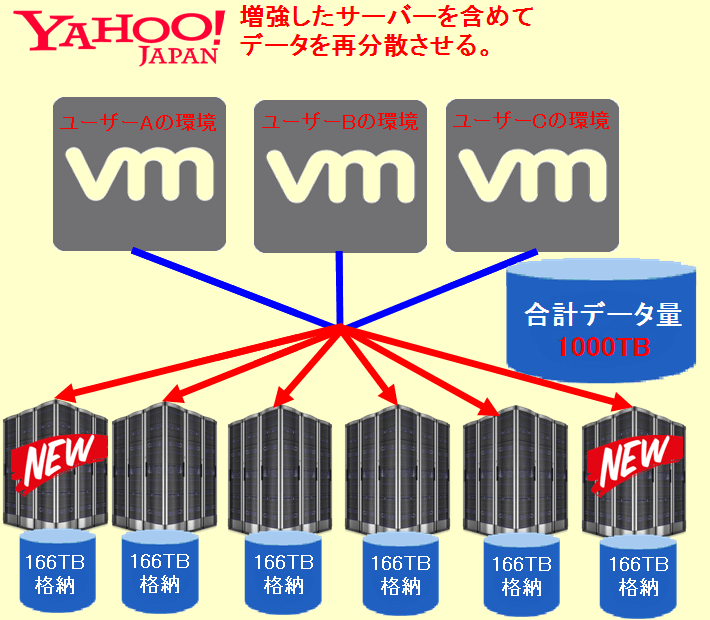
クロネコくんこれが、さっき言っていた分散ストレージ機能を発揮させるための作業ってことか?
サバくんその通りだね。
6.データ再配置処理時のネットワークトラフィックの設定に失敗していた。

クロネコくんつまりは、どういうことなんだ?
分散したサーバーにデータを再配置するために、ネットワーク回線を通じてそれぞれのサーバーへデータ転送が行われます。
当然、Zenlogicのように7万人以上のユーザーが利用しているような場合、そのデータ量は個人使用レベルではとうてい考えられない膨大なものとなります。
そのような膨大なデータ量を何も考えずにネットワーク回線を通じてデータ転送しようとすると、すぐにネットワークが混雑して異常を起こしてしまいます。
そこで、yahooではネットワークトラフィックの設定を事前に行っておき、ネットワークが混雑しないようにデータ転送を行えるようにしていたはずでした。
しかし、このネットワークトラフィックの設定にミスがあり、その結果ネットワークが混雑してしまいサーバー管理者もユーザーアクセス不能(著しくアクセスが遅い)になる事態となりました。
サバくん交通道路で言えば、手配したはずの交通整理員が手違いにより来なくて、道路が渋滞してしまったことになるよ。
7.ネットワークが混在してしまい修復不能となったので、サービスを停止させてのメンテナンスを行った。
ネットワークが混雑して、どうしようも無くなったファーストサーバーとyahooはサービス全体を急遽停止させる決断をしました。
クロネコくんこれが、7月6日~7月9日に起きたサービスの停止ってわけだな。
サービス停止後はネットワークトラフィックなどの設定を再度見直した後、再びデータを格納するサーバー(ストレージ)へデータの再配置処理を行いました。
その結果、障害が解消してサービス再開となり、以後は経過観察となりました。
サバくんまとめになるけど、今回の障害では2つの技術的なミスがあったんだ。
ユーザーが使うデータ量の合計予測を見誤って、データを格納するサーバーの台数を少なくしてしまった。
サバくんこれがそもそもの障害の原因で
ネットワーク設定のミスにより、データを格納するサーバーへのデータの再配置処理でネットワークを混雑させてしましった。
サバくんこれが障害を長引かせて、最後にはサービス停止までしなければならなくなった原因だよ。
クロネコくんなるほどな。ミスにミスが重なった結果がこの大規模障害ってわけなんだな。
今回の障害の原因となった分散ストレージは、ここ数年で実用化の流れに入った技術であり、ベテランのエンジニアでも扱うのはまだまだ難しいとされている技術です。
サーバー管理者であるyahooの技術力を疑うわけではありません。
しかし、yahooが分散ストレージの扱いを甘く見ていた結果、起きてしまった障害であると考えれます。
サバくん今回の障害の原因とサービス停止までさせたのはyahoo側が原因だけど、ファーストサーバーでもマズい対応があったんだ。
クロネコくんマズい対応ってなんだよ?
サバくんそれをこれから説明していくよ。
サービス停止直前のアナウンスにユーザー大不満
障害に対して完全な復旧を行うにはサービス停止した上でメンテナンスをしなければならなかった事については、仕方が無かった事かもしれません。
しかし、サービスを停止する前のユーザーへアナウンスを行ったのが、サービス停止の1時間前という対応については弁解の余地も無いほどのひどい対応です。
このファーストサーバー社の対応には、当然のごとく利用ユーザーからも怒りの声が上がりました。
Zenlogicさんそれはほんとに、マズすぎるんですが。7/6 20:00停止のものを19:15に発表でメールが19:53とかお客様にアナウンスする時間すらありませんよね??! 7分でなにをしろと。。。バックアップも取れない。しかも最長月曜まで全停止ってあり得ない。 https://t.co/PEQ0zcE3VI
— eriko koide (@elico) 2018年7月6日
Zenlogic、本日20:00から全サービス停止の連絡を、19:53分にメールで送ってくるって、アホでしかない。
あと2分で社内アナウンスメールなんか書けへんし送れんやないか。
も、いいです。さようならw— ちゃづけ☆華花推し (@chauzke) 2018年7月6日
また、Zenlogicを利用している長野電鉄でも、突然すぎるサービス停止のアナウンスに怒りの声をあげている。
「緊急メンテナンスの開始6分前に連絡が来るとは。何も手が打てないではないか」。
長野電鉄企画部の担当者はファーストサーバの対応にこう憤る。
長野電鉄では2018年7月6日に発生した集中豪雨に関する運行情報などをwebサイトやメールで利用者に通知しようとしていた。
しかし、突然のZenlogicサービス停止により通知ができず、急遽FAXで使った異例の対応を行う事態となった。
クロネコくんはっきり言って、ファーストサーバーの対応が不味かったってことだな。
サバくん全くもってその通りだよ。せめて1日前にサービス停止のアナウンスをすればまだマシだったんだけど、何を思って1時間前にしたのか理解できないね。
2012年には大規模データ消失事件を起こしていた
ファーストサーバーが今回のような大規模障害を起こしたのは初めてではありません。
実は2012年にもサイト・メール・顧客情報・バックアップといった多種多様なデータを消失させてしまう、こちらもレンタルサーバー業界では前代未聞の事件を起こしています。
データ消失の影響でユーザーは長期間にわたるサイトの閲覧不能・メールの消失・データの消失を被害を受けることになり。
最終的には当時の親会社であるyahooも協力して損害賠償28億4100万円を払う事態となりました。
サバくん僕も2012年に仕事場でファーストサーバーを利用してwebサイトを作っていたけど、この事件があまりに酷すぎてさくらレンタルサーバーへ引越したよ。
クロネコくん2012年以前から今までファーストサーバーを利用していたユーザーは2度信頼を手酷く裏切られたわけか。
サバくんそういうことになるね。さすがに2度大きな信頼を裏切ったファーストサーバーに対する離脱者の大量発生は避けられないだろうね。
ファーストサーバー障害事件を受けて我々ユーザーが学ぶべきこと
今回のファーストサーバー障害事件において、レンタルサーバーを利用する僕たちユーザーが学ぶべきことは以下の4つです。
今回の障害事件から学ぶべきこと
- どのレンタルサーバー会社でも大規模障害が発生する可能性があると認識する
- 更新する度にバックアップを取る癖をつける
- 移行先候補のレンタルサーバー会社を事前に探しておく
- Zenlogicと契約するのはしばらく控える
サバくんいずれもレンタルサーバーを利用していく上で発生するリスクを回避するために必要なことだよ。
どのレンタルサーバー会社でも大規模障害が発生する可能性はある
まず、今回のような障害事件はファーストサーバーだけでなく、どのレンタルサーバー会社でも起こる可能性は0ではありません。
それが例え「さくらインターネット」・「ロリポップ」・「エックスサーバー」などの信頼と実績が十分なレンタルサーバーであっても同じです。
なぜなら、レンタルサーバーもそれに付随するサービスも人間が作ったものである以上、故障したり更新時に失敗する可能性は常にあるからです。
ですので、大規模な障害が発生した場合のリスクを最小限におさえるための備えを日頃からしておくことが大切です。
バックアップを取る癖をつける
大規模な障害が発生した場合のリスクを最小限におさえるための備えの1つとして。
サイトなどの更新を行ったらバックアップを取って、自分のパソコンやGoogleドライブなどに保存しておく癖をつけましょう。
今回のファーストサーバー障害事件のように、ユーザーがバックアップを取る暇もなくサービスが停止する事態もあります。
ですので、更新を行ったらバックアップを取って、利用しているレンタルサーバー以外の場所に保存しておくことが大切です。
サバくんバックアップがあれば、いざという時に他のレンタルサーバーへの移行ができるよ。

移行先候補のレンタルサーバー会社を探しておく
今自分が使っているレンタルサーバーが1社だけの場合。
そのレンタルサーバー会社が障害を起こして利用できなくなる可能性も考えて、移行先候補のレンタルサーバー会社を事前に1社以上探しておきましょう。
移行先候補のレンタルサーバー会社を見つけておけば、今使っているレンタルサーバー会社で大規模障害が発生した時でもスムーズな移行ができるので焦らなくて済みます。
サバくんレンタルサーバーは契約したら即使えるようになるから、移行先候補のレンタルサーバー会社とは常に契約しておかなくても大丈夫だよ。
Zenlogicとの契約は控える
今回の障害事件はひとまず終息しましたが、レンタルサーバーというものは1年~2年くらいは安定稼動していないと信用することはできません。
ですので、Zenlogicとの契約は最低でも1年半後となる2020年までは利用を控えるのが、レンタルサーバーを利用する上での最大のリスク回避になります。
クロネコくん確かにこんな障害が発生した以上、Zenlogicとの契約する気は今のところ全く起きないな。
サバくんZenlogicの代わりに以下のレンタルサーバー会社と契約するのがおすすめだよ。
個人向きでおすすめのレンタルサーバー会社
- エックスサーバー
- ConoHa WING
- ロリポップ
- Mixhost
- ヘテムル



法人向きでおすすめのレンタルサーバー会社
- さくらインターネット(専用サーバー)
- カゴヤ・ジャパン(マネージド専用・専用サーバー)
- CPI(マネージド専用サーバー)
- シックスコア
まとめ
今回のファーストサーバーの大規模障害は3日間のサービス停止という、国内のレンタルサーバーにおいては類を見ない最悪レベルの障害となり、Zenlogicを利用していたユーザーは月額費用の返金程度はとうてい取り戻せない大損害を受けることになりました。
今回、被害を受けたZenlogicのユーザーは嫌というほどレンタルサーバーを借りる上でのリスクを感じ、既にリスク回避を実践されているかと思います。
しかし、Zenlogic以外のレンタルサーバーを利用しているユーザーであっても、今回の障害事件からレンタルサーバーにおけるリスクを改めて認識して。
サイトを更新したらバックアップを取る、移行先のレンタルサーバー会社を事前に探してキープしておくなど。障害が発生したときのリスク回避の備えをしておくことが、レンタルサーバーを利用していく上で非常に大切なことではないかと僕は思います。
サバくんレンタルサーバーを使って運営しているサイトなどは自分の資産も同然だよ。だからこそ自分の資産を守れる備えは常にしておこう。
この記事はここまです。
最後まで読んで頂きありがとうございました。
コメント